No OpenAI Account, No Problem!
If you want the OpenAI developer experience without the OpenAI account (or tokens), Ollama now exposes an OpenAI-style /v1 endpoint. That means you can point existing clients and frameworks at your local models and ship.
Condensed mini-blog from my piece on crafting your own OpenAI-compatible API with Ollama.
Why this rocks
- Drop‑in compatibility: Keep using the OpenAI SDKs and patterns.
- Local first: Your data and prompts stay on your machine.
- Costs: $0 per token, just your hardware.
1) Spin up Ollama with Docker
CPU only
GPU (NVIDIA)
- Install NVIDIA Container Toolkit.
- Run with GPU access:
docker run -d --gpus=all -v /data/ollama:/root/.ollama --restart always -p 11434:11434 --name ollama ollama/ollama
Pro tip: Want specific GPUs? Use --gpus "device=0,1".
Where are models stored? In this compose, they’ll live on your host at /data/ollama.
2) Sanity‑check Ollama
Run a model inside the container:
Hit the OpenAI‑style chat completions endpoint:
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama2",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
}'
If you get a response with choices[0].message.content, you’re golden.
3) Build a local “OpenAI” chatbot
Requirements
streamlit>=1.28
langchain>=0.0.217
openai>=1.2
duckduckgo-search
anthropic>=0.3.0
trubrics>=1.4.3
streamlit-feedback
Minimal app: Chatbot.py
from openai import OpenAI
import streamlit as st
# This key is required by the SDK but unused by Ollama; leave any string
OPENAI_API_KEY = "ollama-baby"
st.title("Chatbot")
st.caption("A Streamlit chatbot powered by OpenAI API... I mean Ollama!!!")
if "messages" not in st.session_state:
st.session_state["messages"] = [
{"role": "assistant", "content": "How can I help you?"}
]
# Show history
for msg in st.session_state["messages"]:
st.chat_message(msg["role"]).write(msg["content"])
# Input
prompt = st.chat_input("Say something…")
if prompt:
client = OpenAI(
api_key=OPENAI_API_KEY,
base_url="http://localhost:11434/v1", # ← point at Ollama
)
st.session_state["messages"].append({"role": "user", "content": prompt})
st.chat_message("user").write(prompt)
response = client.chat.completions.create(
model="llama2",
messages=st.session_state["messages"],
)
msg = response.choices[0].message.content
st.session_state["messages"].append({"role": "assistant", "content": msg})
st.chat_message("assistant").write(msg)
Run it:
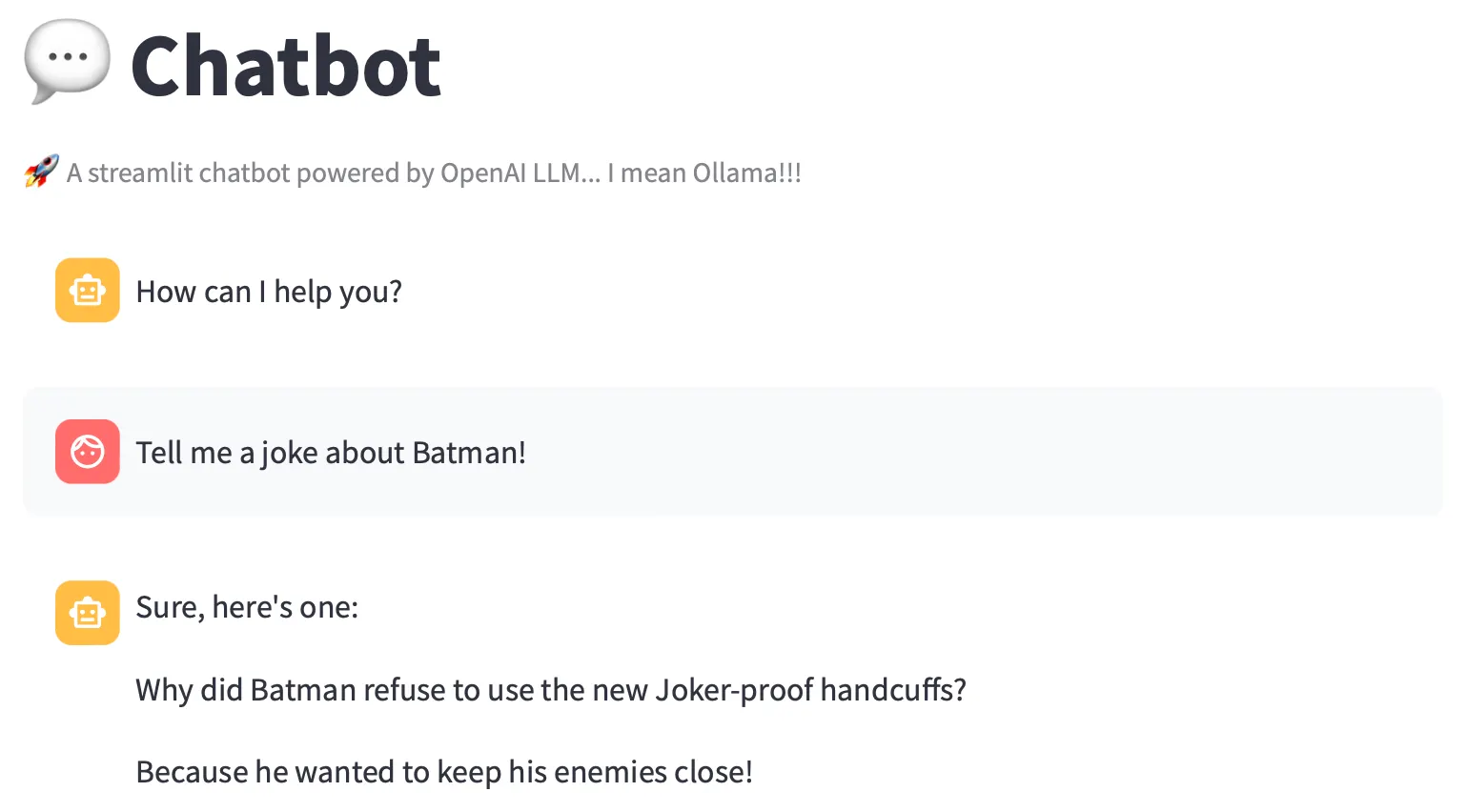 Still not a standup comedian 😬
Still not a standup comedian 😬
Notes
- You can swap
llama2for any local model you’ve pulled with Ollama. - Keep an eye on VRAM/CPU footprints; bigger models need beefier hardware.
- LangChain, agents, and retrieval components can ride along since the client looks like OpenAI.
Wrap‑up
With Ollama’s /v1 endpoint, you can prototype and ship OpenAI‑compatible apps locally. The DX you know, the privacy you want, and zero token anxiety.
📖 Read the Full Article

No OpenAI Account, No Problem! Crafting Your Own OpenAI API with Ollama 🦙
Explore alternatives to OpenAI's services and learn how to leverage open-source models for your AI projects.
📖 Full article available on Medium